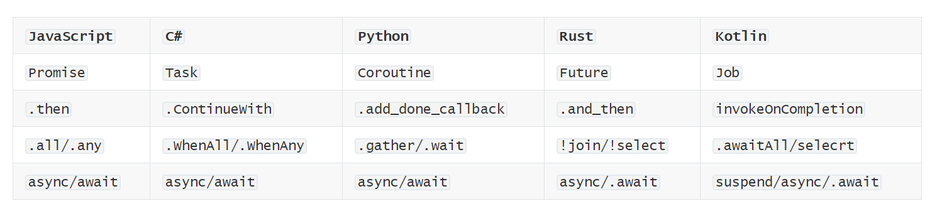
异步编程概览
前言
简单了解异步编程的概念,介绍异步编程的多种实现,并介绍常用编程语言的异步支持。
什么是异步
通常来说,程序都是顺序执行,同一时刻只会发生一件事。如果一个函数依赖于另一个函数的结果,它只能等待那个函数结束才能继续执行,从用户的角度来说,整个程序才算运行完毕.
Mac 用户有时会经历过这种旋转的彩虹光标(常称为沙滩球),操作系统通过这个光标告诉用户:“现在运行的程序正在等待其他的某一件事情完成,才能继续运行,都这么长的时间了,你一定在担心到底发生了什么事情”。

这是令人沮丧的体验,没有充分利用计算机的计算能力 — 尤其是在计算机普遍都有多核CPU的时代,坐在那里等待毫无意义,你完全可以在另一个处理器内核上干其他的工作,同时计算机完成耗时任务的时候通知你。这样你可以同时完成其他工作,这就是异步编程的出发点。
阻塞和非阻塞、同步和异步
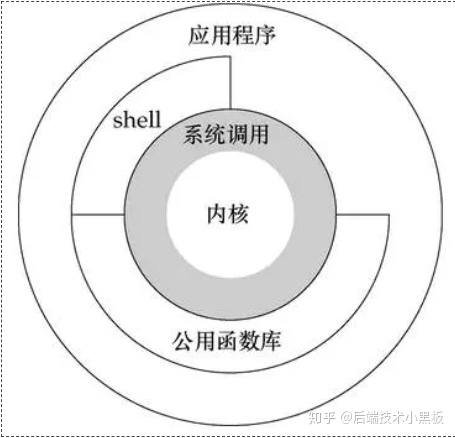
基础知识预备: 用户态和内核态
用户态:也称为用户空间,即上层应用程序的活动空间,应用程序的执行必须依赖于内核提供的资源
内核态:也称为内核空间,控制计算机的硬件资源,并提供上层应用程序运行的环境
注:用户态可以通过系统调用切换到内核态,这是主动进入到内核态。此外在出现异常或者外围设备的中断也会进入到内核态,不过是被动响应的
先说结论:各种IO模型其实是根据它在上述两个阶段的不同表现(用户进程或者线程是否阻塞)来区分的!!!在第一个阶段用户进程是否阻塞用来区分阻塞/非阻塞,在第二个阶段用户是否阻塞用来区分同步/异步!!!
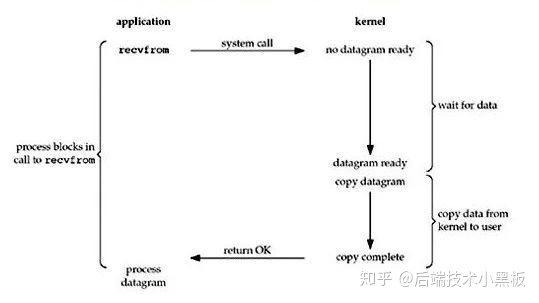
- 阻塞
数据-内核-用户的两个阶段 都是阻塞执行的, 内核等待数据就绪,用户等待内核就绪, 然后一一执行。
- 非阻塞
与阻塞IO类似,但是不同点在于用户层的调用会立马接收到一个带有error的状态,告知用户层还没准备好数据,用户层会再次的进行调用,直到从内核层获取正确的结果或者失败。需要注意的是, 数据在从内核-用户的过程中,用户进程仍然是阻塞的。
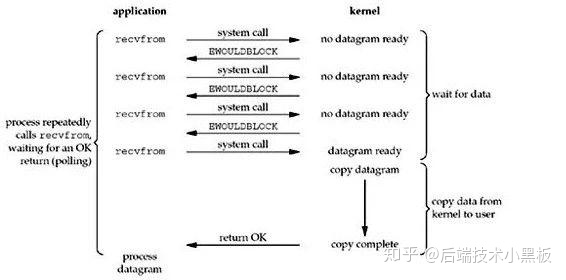
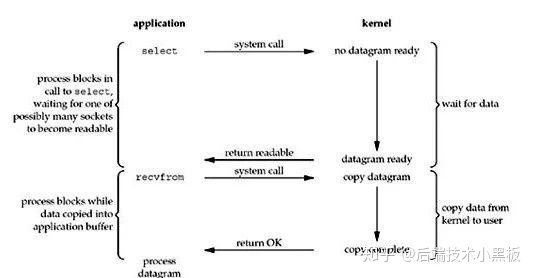
- 多路复用
IO多路复用实际上是通过select/epoll等函数轮询多个socket,当用户进程调用了select函数,整个用户进程就会被阻塞,直到收到数据准备就绪的返回后续的操作和非阻塞IO是类似的,由于在获取数据的系统调用之前,需要的数据就已经准备就绪了,所以第一个阶段是非阻塞的;第二个阶段(也就是用户实际获取数据的调用)同样还是阻塞的。
所以IO多路复用整个过程中,用户进程都是阻塞的.
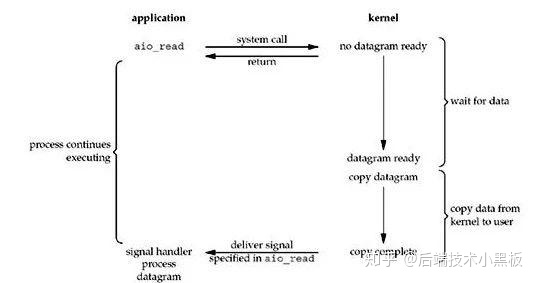
- 异步
异步IO实际上是用户进程发起read操作之后,就会立刻收到一个返回,所以用户进程就可以去完成其他的工作,而不需要阻塞;直到数据准备就绪并且完成了从内核空间向用户空间拷贝的工作,这时用户进程会收到一个通知,告诉他read操作已完成整个过程中用户进程不会被阻塞。
编程模型
- 同步编程模型

假如操作系统可以提供多个线程的话,那么就会变成这样

- 异步编程模型
与同步模型不同的是,这里的线程在某个任务开始时会保存当前的上下文也就是类似的context,并可以开始继续执行下一个任务。一个最简单的单线程异步执行过程可能长这样:

虽然我们可以设计成将资源、任务以及处理器都存在于一个单独线程中,但异步同样支持多线程模型。
异步使用场景
异步适合 CPU 不密集但是 I/O 密集的场景。
举个例子:爬虫。 在编写一个爬虫程序的时候,需要访问N个url并且处理返回的网页内容。这个例子和上面“读取并处理多个文件的内容”非常相似,网络I/O和磁盘I/O都属于慢速场景,如果访问完一个url再访问下一个,CPU大部分时间都在等待。造成了资源浪费。这里可以采用异步的方式编写代码或使用多线程并行访问并处理每个url。 对于高性能计算的场景, 如音视频解码、计算圆周率等,这时使用异步IO的调度反而会带来大量的性能浪费甚至不如顺序执行,这时使用多线程利用多核心同时计算便是最优解了。
异步实现
异步的主要实现方式:
- 回调
首先是最朴素的异步实现-回调:回调函数就是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应。
func doSomeThingAsync(callback Callback) {
// 很多很多工作完成后...
callback(val)
}
但是回调函数有很多显而易见的缺点,如回调地狱、栈空间的问题存在。
假设我们约定一种编程规范,所有的函数都按照上述的方式来定义,即所有的函数都直接返回结果值,而是在参数列表最后的位置传入一个 callback 函数参数,并在函数执行完成时通过这个 callback 来处理结果,这种代码风格被称为延续传递风格(Continuation Passing Style)。这里的回调函数(callback)被称为是延续(continuation),即这个回调函数决定了程序接下来的行为,整个程序的逻辑就是通过一个个的延续而拼接在一起。
但是callback对于计算任务看起来是没有任何问题的,这也仅限于计算,一旦涉及到IO时,continuation便有了存在的意义。
先看一段BIO的代码:
var input = recv_from_socket() // Block at syscall recv()
var result = calculator.calculate(input)
send_to_socket(result) // Block at syscall send()
由于recv_from 以及 send 操作都会block,所以直到IO就绪,都会block在这里,浪费资源,这时引入AIO可以很好解决这个问题,于是这段代码现在变成了这样:
recv_from_socket((input) -> {
var result = calculator.calculate(input)
send_to_socket(result) // ignore result
})
现在,线程便不会因为IO阻塞。
- Promise/Future/Delay/Deferrd
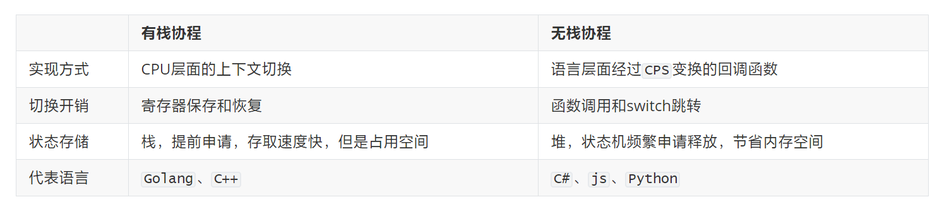
在许多支持异步编程的语言中,都能看到这些概念的存在,但是含义却不尽相同,其中promise和future便是不同的东西,但是他们的共同点-有限状态机。他们也叫无栈协程。
Promise字面意义上是承诺,他把异步IO抽象成这样一种特性的状态机对象:
- 它结果不会立即得到:需要间隔一段时间,结果可以通过一个“延时对象”间接的取得
- 它可以组合:可以在成功以后继续驱动其他的状态机,也就是与其他的异步操作相串联
- 它的结果可以成功,也可以错误
经过抽象,JavaScript中的Promise被设计成了一个仅仅具有三种状态的极简状态机,分别是Pending等待状态,Reject错误状态和Resolve成功状态。需要注意的是,Promise状态机还提供了一个next(callback)连结我们下一步的操作。
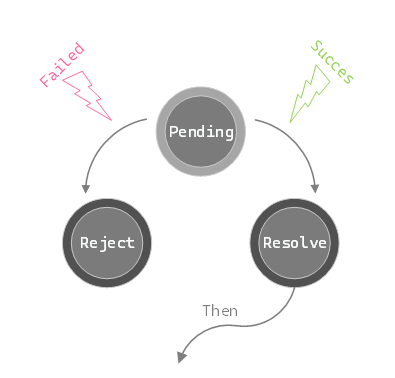
通过使用Promise我们可以不断在then的回调函数之中返回下一步操作的Promise状态机,本来需要按部就班运行的异步操作可以像链条一样链接起来,向下逐个运行!
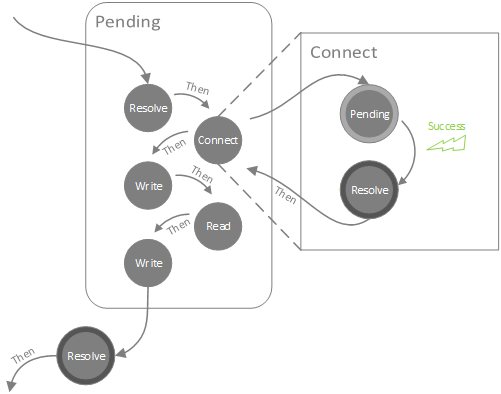
- async/await
在某种意义上前后串联的Promise状态机已经是一种同步代码了。
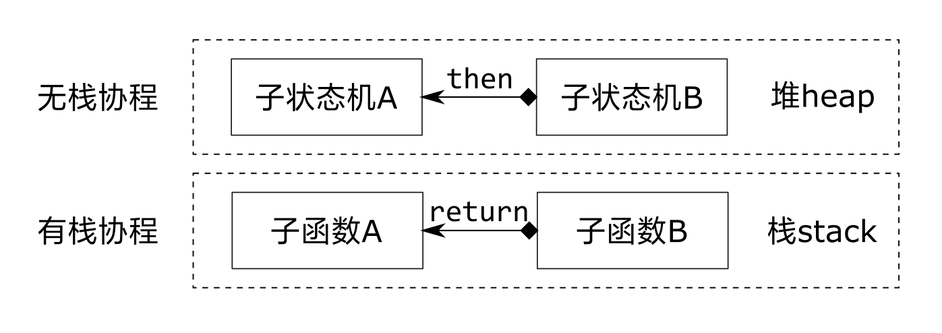
由于许多语言都已经实现了Async/Await,但是通俗的说"async/await是CPS变换的语法糖"是没有问题的(部分语言除外)。只不过动态语言中几乎都是变为无栈协程,而在偏向静态语言中,一般则变换为有栈协程。也被叫做绿色线程。
异步任务调度器
从一个高度抽象的角度来看待异步任务调度的话, 那么可以总结为:
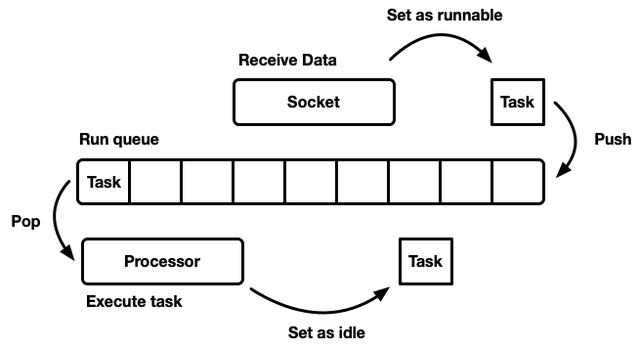
其中我们可以看到,最为重要的就是其中的队列, 关于如何在这个队列Push和Pop,这就要具体到某个特定的实现来说。除此之外这里的队列也是一个抽象的概念,后面我们将会逐渐的解读。
在Node中异步任务的调度是基于Event loop进行的,最终的实现是"libuv"的多平台C语言库,提供了对epoll、Windows的IOCP、kqueue等支持,浏览器中的async实现并不完全一样,有兴趣可以了解babel是如何编译的。
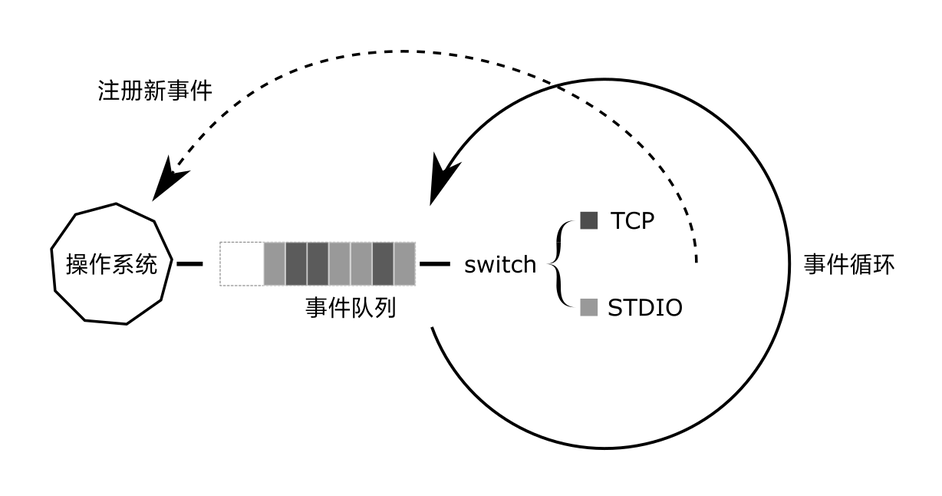
从node理解async/await的过程之中都是基于我们所说的CPS变换,这种方式实现的异步任务的调度归根结底还是回调函数。在js这种单线程的语言之中,再多的异步任务也只能一次运行一个。
这里我们提及Rust, Rust在设计之初并没有完善异步任务的调度器,而是只实现了基础任务Future,调度的实现交由社区进行。通过Rust的异步运行时调度Tokio设计,我们也可以了解在单线程和多线程的不同设计。
现代计算机都具有多个 CPU 以及多个物理核,使用单线程模型会严重得限制资源利用率,所以为了尽可能压榨所有CPU或物理核的能力,就需要:
- 单一全局的任务队列,多处理器
- 多任务队列,每个都有单独的处理器
单一队列多处理器的设计必须支持多生产者、多消费者,但是多消费者同样也会造成数据竞争。
多任务队列可以参考"窃取式调度", 在Golang语言中, 关于其goroutine的GPM调度便是一种实现。
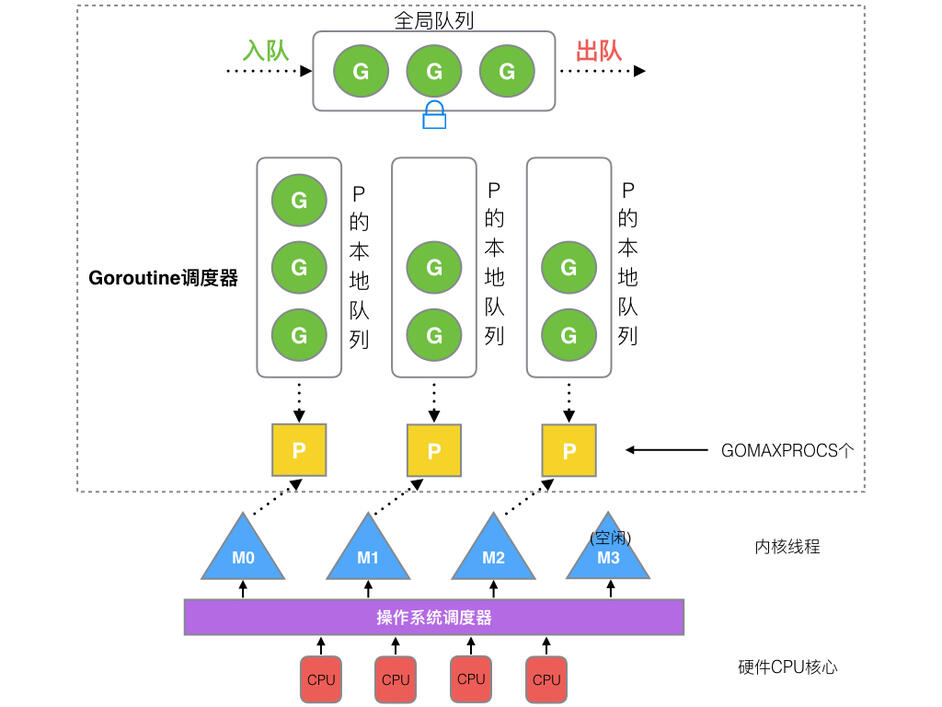
每个Processor维护一个队列,goroutine按照一下的顺序进行"窃取"任务
- 从本地队列获取任务
- 从全局队列获取任务
- 从网络轮询器获取任务
- 从其它的处理器的本地队列窃取任务
(非)主流编程语言的异步支持