MySQL 索引指南
索引定义
MySQL官方对索引的定义为:索引(index)是帮助MySQL高效获取数据的数据结构(有序)。索引是在数据库表的字段上添加的,是为了提高查询效率存在的一种机制。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据, 这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
索引优势
- 加快查找和排序的速率,降低数据库的IO成本以及CPU的消耗
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
索引劣势
索引实际上也是一张表,保存了主键和索引字段,并指向实体类的记录,本身需要占用空间
虽然增加了查询效率,但对于增删改,每次改动表,还需要更新索引
- 新增:自然需要在索引树中新增节点
- 删除:索引树中指向的记录可能会失效,意味着这棵索引树很多节点,都是失效的
- 改动:索引树中节点的指向可能需要改变
索引类型
BTREE索引 : 最常见的索引类型,大部分索引都支持 B 树索引。HASH索引:只有Memory引擎支持 , 使用场景简单。R-tree索引(空间索引):空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少,不做特别介绍。Full-text(全文索引) :全文索引也是MyISAM的一个特殊索引类型,主要用于全文索引,InnoDB从Mysql5.6版本开始支持全文索引。
| 索引 | INNODB引擎 | MYISAM引擎 | MEMORY引擎 |
|---|---|---|---|
| BTREE索引 | 支持 | 支持 | 支持 |
| HASH 索引 | 不支持 | 不支持 | 支持 |
| R-tree 索引 | 不支持 | 支持 | 不支持 |
| Full-text | 5.6版本之后支持 | 支持 | 不支持 |
我们平常所说的索引,如果没有特别指明,都是指B+树(多路搜索树,并不一定是二叉的)结构组织的索引。其中聚集索引、复合索引、前缀索引、唯一索引默认都是使用 B+tree 索引,统称为索引。
B树和B+树
B Tree指的是Balance Tree,也就是平衡树。平衡树是一颗查找树,并且所有叶子节点位于同一层。B+ Tree是基于B Tree和叶子节点顺序访问指针进行实现,它具有B Tree的平衡性,并且通过顺序访问指针来提高区间查询的性能。 在B+ Tree中,一个节点中的key从左到右非递减排列,如果某个指针的左右相邻key分别是 keyi 和 keyi+1,且不为null,则该指针指向节点的所有key大于等于 keyi 且小于等于 i+1。
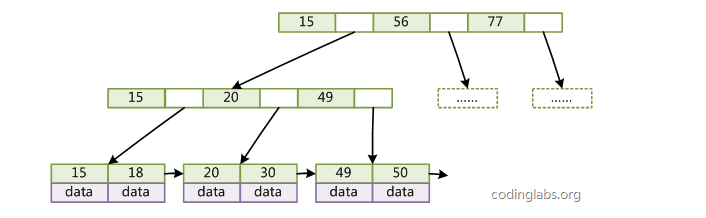
索引分类
在InnoDB中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。又因为前面我们提到的,InnoDB使用了B+树索引模型,所以数据都是存储在B+树中的。
主键索引
数据表的主键列使用的就是主键索引,且会默认创建。主键索引的叶子节点存的是整行数据。在InnoDB里,主键索引也被称为聚簇索引(clustered index)。
非聚簇索引
辅助索引的叶子节点内容是主键的值。在InnoDB里,辅助索引也被称为二级索引(secondary index)。
- 主键索引存放了整行数据
- 辅助索引只存放了自己本身,以及id主键用于
回表查询
当所要查询的数据,刚好就是索引树上存在的,此时称之为覆盖索引
二级索引分类
唯一索引(Unique Key):唯一索引也是一种约束。唯一索引的属性列不能出现重复的数据,但是允许数据为NULL,一张表允许创建多个唯一索引。 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。普通索引(Index):普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和NULL。前缀索引(Prefix):前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小, 因为只取前几个字符。全文索引(Full Text):全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。MySQL5.6之前只有MYISAM引擎支持全文索引,5.6 之后InnoDB也支持了全文索引
索引下推
索引下推意味推迟回表操作:先在自身索引树上判断是否满足其他的判断条件,不满足则直接忽略掉,不进行回表的操作。
最左前缀原则
来自于MySQL官方文档对于联合索引的定义:
MySQL can use multiple-column indexes for queries that test all the columns in the index, or queries that test just the first column, the first two columns, the first three columns, and so on. If you specify the columns in the right order in the index definition, a single composite index can speed up several kinds of queries on the same table.
如果表拥有一个联合索引,任何一个索引的最左前缀都会被优化器用于查找列。比如,如果你创建了一个包含三列的联合索引 (col1, col2, col3),你的索引生效于 (col1), (col1, col2), and (col1, col2, col3)。顺序并不由where前后决定,因为优化器会自动
假设我们存在这样一个表, 定义了一个索引名为name:
CREATE TABLE test (
id INT NOT NULL,
last_name CHAR(30) NOT NULL,
first_name CHAR(30) NOT NULL,
PRIMARY KEY (id),
INDEX name (last_name,first_name)
);
name 是一个包含了 last_name 和 first_name 列的联合索引。该索引可以用于 last_name 和 first_name 指定的一个范围的查询,也可以只用于只指定了 last_name 列的查询,因为这个列是索引的一个最左前缀,因此索引 name 可以用于下列的查询语句:
SELECT * FROM test WHERE last_name='Jones';
SELECT * FROM test
WHERE last_name='Jones' AND first_name='John';
SELECT * FROM test
WHERE last_name='Jones'
AND (first_name='John' OR first_name='Jon');
SELECT * FROM test
WHERE last_name='Jones'
AND first_name >='M' AND first_name < 'N';
然而,索引 name 不能用于下面的查询:
# 不符合最左前缀匹配 但仍然会走索引 此时情况为覆盖索引
SELECT * FROM test WHERE first_name='John';
SELECT * FROM test
WHERE last_name='Jones' OR first_name='John';
索引设计原则
- 针对表
查询频次高,且数据量多的表
- 针对字段
最好从where子句的条件中提取,如果where子句中的组合比较多,那么应当挑选最常用、过滤效果最好的列的组合。
其他原则
- 最好用唯一索引,区分度越高,使用索引的效率越高
- 不是越多越好,维护也需要时间和空间代价,建议单张表索引不超过 5 个
因为 MySQL 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
推荐建立索引
- where中的查询字段
- 查询中与其他表关联的字段,比如外键
- 排序的字段
- 统计或分组的字段
不推荐建立索引
- 表中数据量很少
- 经常改动的表
- 频繁更新的字段
- 数据重复且分布均匀的表字段(比如包含了很多重复数据,那此时多叉树的二分查找,其实用处不大,可以理解为
O(logn)退化了)